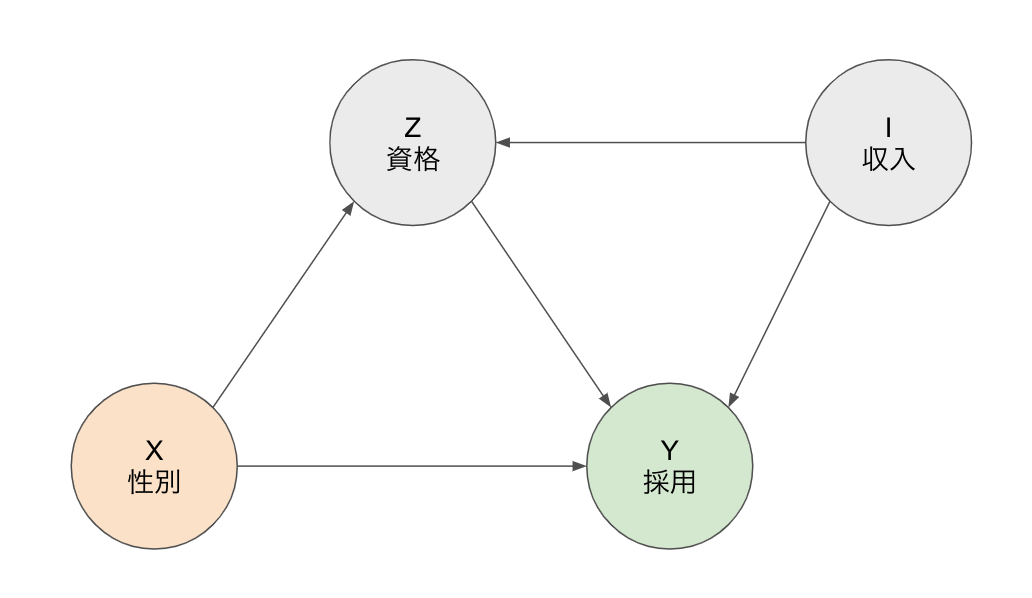
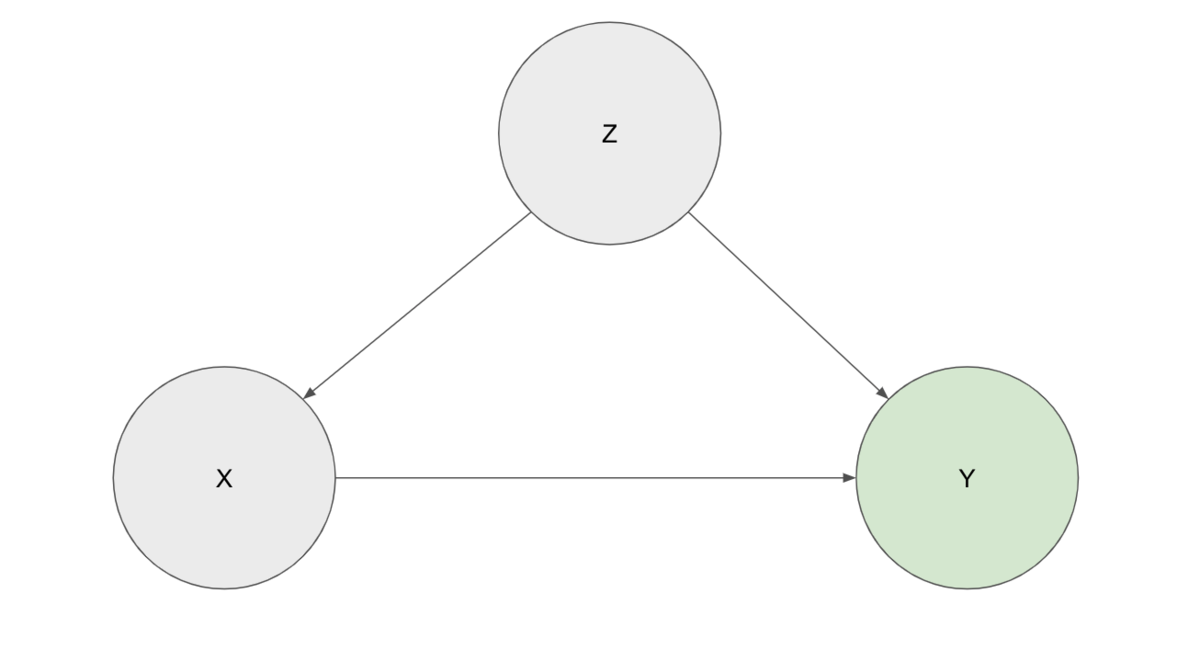
『データ指向アプリケーションデザイン』を読んで特に印象に残ったところをメモとして残します。分厚いので数回に分けます。
書籍が素晴らしいので、詳細はそちらを読んでみてください。

はじめに
データ指向とは、データの量や複雑さ、変化の速度が主な課題となるアプリケーションのことを指す。目的を達成するためにどのような種類の技術を用いるのが適切か的確に判断し、優れたアプリケーションのアーキテクチャ基盤を構築するためのツール群の組み合わせ方を理解できるようになることを目指す。
1章 信頼性、スケーラビリティ、メンテナンス性に優れたアプリケーション
ソフトウェアシステムにおける重要な3つの課題
- 信頼性。システムは障害があったとしても正しく動作し続けるべき。
- スケーラビリティ。データ量の増加、トラフィック量の増加などといった成長に対して、無理のない方法で対応可能であるべき。
- メンテナンス性。時間が経つにつれて多くの人が関わるが、それらの人がシステムに生産的に関われるべき。
2章 データモデルとクエリ言語
リレーショナルモデルとドキュメントモデル
ドキュメントデータモデルの良さは以下のような点
- スキーマの柔軟性
- ローカリティから来る優れたパフォーマンス
- データ構造がアプリケーションのものに近い場合がある
特にアプリケーションの構造が一体多の関係からなるツリー構造を持ち、そのツリー全体が通常は一度にロードされる場合、ドキュメントデータモデルを利用するのは良い考えとなる。 その一方で、アプリケーションが多対多の関係を必要とするなら、ドキュメントモデルの魅力は薄れる。
多くのドキュメントデータベースにおけるJsonサポートでは、ドキュメント内におけるスキーマを強制しない。スキーマがないということは、任意のキーとバリューをドキュメントに追加できるということ。スキーマレスという言葉がよく使われるが、厳密には スキーマオンリード (データ構造は暗黙的であり、データの読み取り時に解釈される)であり、逆にリレーショナルデータベースなどでは スキーマオンライト と呼ばれている。スキーマオンリードはドキュメントの構造が統一されていない場合にはメリットとなる。
3章ストレージと抽出
データベースを駆動するデータ構造
データベースから特定のキーの値を効率的に見つけるためにはインデックスが必要となる。インデックスがない場合は O(n) の計算コストがかかり、スケーラブルではない。インデックスは、データから作られる追加のデータ構造として存在している。
インデックスはデータの書き込みのたびに更新する必要があるため、書き込み速度を低下させる。読み出しクエリは高速にしてくれるので、重要なトレードオフとなる。
インデックスの管理方法にはいくつか種類がある。
- ハッシュインデックス。インメモリのハッシュマップの中には、全てのデータに対してデータファイル中のバイトオフセットをマッピングする。こうすることで、ディスクに保存されているファイルのどの場所に目的のデータがあるか検索することができる。ファイルが一定の大きさを超えると、新しくセグメントファイルを作成して新しい書き込みは新しいファイルへと行う。とはいえ、このインメモリハッシュマップがメモリに収まり切る必要がある。
- SSTable(Sorted String Table)。SSTableはファイルの中身がキーでソートされている。この場合は全てのデータをインメモリに持つ必要はない。なぜなら、それぞれのファイルの先頭の単語だけわかれば、どのセグメントファイルにアクセスすれば良いかわかるため。このログ指向ファイルシステムから構築されたインデックス構造はLSMツリー(Log-Structured Merge-Tree)と呼ばれる。
- Bツリー。SSTableと同様に、キーとバリューのペアをキーでソートされた状態で保持する。n個のキーを持つBツリーの深さは常に O(logn) となる。ログ型のインデックス構造とは異なり、データを上書きする。
一般的に、SSTableから構築されたインデックスのLSMツリーは書き込みを高速に処理でき、Bツリーは読み取りが高速に行えるものとみなされている。ただし、LSMツリーではファイルのコンパクション処理が実行中の読み書きに影響を与える場合や、書き込みを受け付けるペースに対してコンパクションが追いつかなくなる可能性に注意が必要となる。
列指向ストレージ
多くのオンライン分析処理データベース(OLAPデータベース)では、ストレージは行指向でレイアウトされている。CSVを想像するとイメージがしやすい。その一方で、データウェアハウスでは列指向ストレージを用いている。一つの行に含まれる値をまとめて保持するのではなく、それぞれの列に含まれる全ての値を保存する。
列指向ストレージの特徴の一つとして、圧縮が容易という点がある。しばしば一つの列の中のuniqueな値は行数に比べて小さくなるので、それに対応するビットマップエンコーディングを行うことで圧縮することができる。
4章 エンコーディングと進化
後方互換性と前方互換性
システムの構築は、変化に容易に適合できるようにするべきである。これを進化性と呼ぶ。システムが進化性を保ち動作し続けるためには、互換性に気をつける必要がある。
後方互換性は、新しいコードを書く人が古いデータを知っていれば対応可能。一方で前方互換性は新しいデータで追加された分を古いコードが無視する対応が必要なので比較的難しい。
これらの互換性は、例えばローリングアップデート中を考えるとサポートする必要性をイメージしやすい。
言語固有のフォーマット
Javaの java.io.Serializable Rubyの Marshal Pythonの pickle など、プログラミング言語自体がインメモリオブジェクトをバイト列にエンコードする機能を持つことも多い。これは特定のプログラミング言語と密に結合しており、他の言語でデータを読むのが難しくなってしまう。一時的な目的を除いて、特定の言語の組み込みエンコーディングを使うのは良くない考え。
Json, XML のバイナリエンコーディング
Json と XML はバイナリ文字列をサポートしていない。そのため、Base64を使ってバイナリデータをエンコードする方法が使われる。これは正しく動くが、データサイズが33%増加してしまう。
Json や XML はバイナリフォーマットと比べると多くの容量を使用するため、バイナリエンコーディングも開発されている(例:Jsonにおける MessagePack)。しかし、削減できる容量はわずかであり、それだけのために人間が読めないフォーマットにする価値があるかは怪しい。
Protocol Buffers
Protocol Buffers (protobuf) は Google で開発されたライブラリで、バイナリエンコーディングのライブラリ。エンコードするデータに対するスキーマを必要とする。エンコーディング後のデータはフィールド名をバイト列に含まないという点で、MessagePack のような Json のバイナリエンコーディングと大きく異なる。その代わりに1, 2, 3...という数値がフィールドタグとして割り当てられる。この数値はスキーマ定義に書かれている数値であり、スキーマ定義があることによるフィールド名そのものを書くことなくフィールド名を特定することができる。
Protocol Buffers におけるスキーマの進化
Protocol Buffers はどのようにして後方・前方互換性を保ちつつスキーマの変化を扱うのだろうか。
エンコードされたレコードは単にバイナリエンコードされたフィールドを繋げたものにすぎない。それぞれのフィールドはフィールドタグで識別され、データ型が付与される。つまりフィールドタグが非常に重要。タグを変更するとエンコード済みの既存の全データが不正なものとなってしまうため、フィールド名を変更することはできるがフィールドタグは変更できない。
前方互換性
新しいタグ番号を使用することによって、スキーマには新しいフィールド加えることができる。古いコードでは認識できないタグ番号を持つ新しいフィールドを無視する。参考:https://developers.google.com/protocol-buffers/docs/proto3#updating
後方互換性
古いフィールドは新しいコードでも読み取ることができる。注意が必要なのは、古いフィールドを新しいコードでも読み取るために、新しく追加するフィールドは必須にできないという点。
")